EVA Architecture
EVA Architecture
EVA's architecture in a nutshellThis page provides an overview of EVA's architecture. The tech structure, how it functions, events and messaging, open source frameworks used, and more.
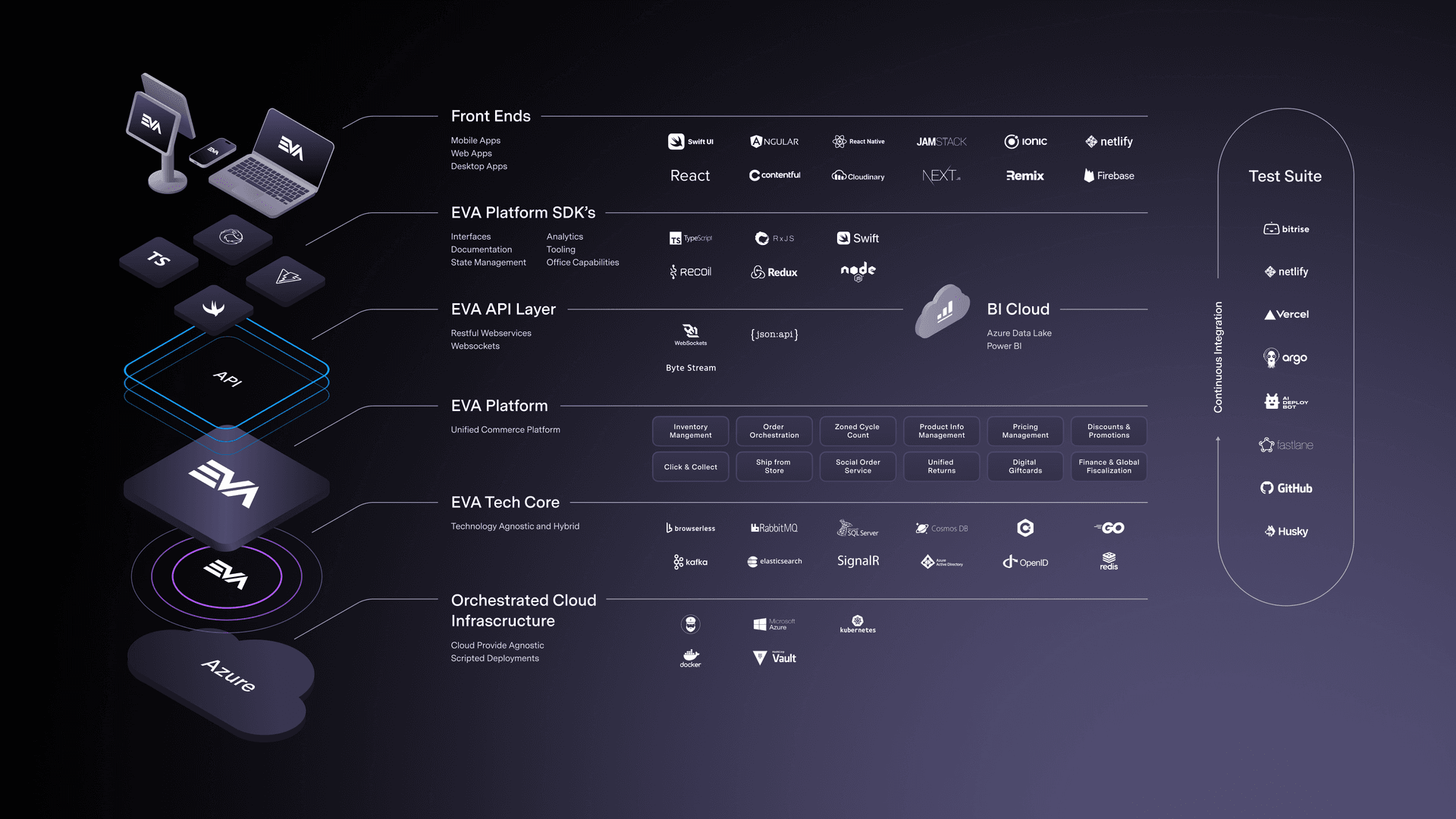
Microservices and their bounded context
EVA is not a microservice platform. The core of EVA platform offers all available functionalities but can be surrounded by separate (micro)services that provide additional functionalities or enhance existing ones. The EVA platform is designed to effortlessly adopt the latest backend applications, frontend frameworks, and innovative solutions.
API’s with descriptive endpoints
You can explore the EVA API using the Service Explorer tool known as DORA.
API reference
A list of all services: API reference
Technical tenant structure for multi-tenant setups
To support multi-tenant set-ups, EVA follows these principles:
- Every EVA tenant is hosted separately, meaning no resources or data structures are shared between our customers. Environments (development, test and staging) are kept completely separated. However, some processing resources may be shared within your organization environments (for example, between your development and test environments).
- Environments within EVA are scripted for swift and easy deployments.
- Hierarchical Organization structure, such as region, country, and store, can be designed within EVA environments. This hierarchy facilitates permission controls and role management.
- Authentication can be based on the default EVA authentication mechanism, but can also be linked to external parties (OAuth/OpenID).
- EVA environments can be hosted in a multi-region setup, where one region serves as the primary source of truth for your organization setup and settings. Other regions, known as Slave regions, can then function independently and periodically report transactions to the Master region.
- Users can be allowed to act globally and log in to every region (Single Sign-On). This flexibility extends to other data aspects, all tailored to support your specific business requirements.
Event architecture
EVA is an event and message driven platform. Nearly every API request generates one or more (event) messages distributed through the message-broker (RabbitMQ). Consumers in the core application or add-ons (Plugins) can act on these messages, enhancing core functionality.
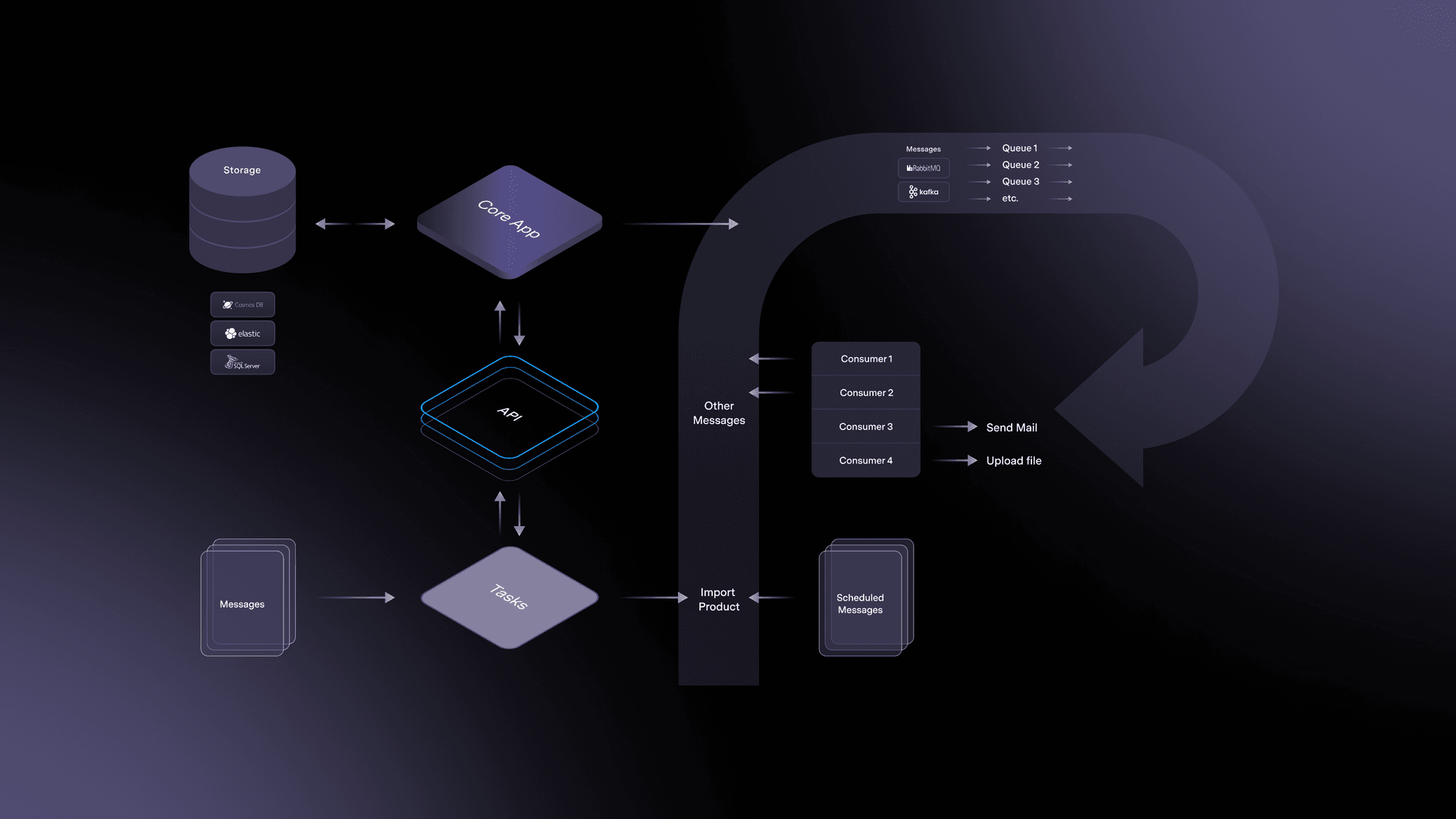
Orchestration patterns used for microservices
EVA is a “Contextual” driven service platform. Services are orchestrated based on context and depend on context within the named processes. For example, “add a product to the shopping basket” triggers new processes to validate order and customer requirements. As a result, microservices in EVA aren't orchestrated like those in a typical microservices platform.
You can explore this setup in the SDK and DORA documentation.
Open source frameworks and rationale
The EVA platform is built with the best of technology available, which is why the core uses a variety of open source frameworks and libraries.
- Elasticsearch: The standard for searching documents, supporting product catalog (PIM) searches, order processing, user databases, and more. Every change in any of those is mirrored to Elastic for fast and convenient searching.
- Redis: A fast key-value store used for user session data and short-lived caching.
- RabbitMQ: The foundation of EVA's eventing and messaging architecture.
Concurrency control through horizontal scalability
EVA implements horizontal scalability and load balancing for database concurrency. This “multiple pods hit first” approach helps balance loads, manage concurrency more effectively, enhance the platform's scalability and fault tolerance, maintain data integrity, and provide a more resilient and efficient platform.
Horizontal Scalability
EVA makes use of horizontal scalability (or scaling out). This involves scaling instances (pods) out and in to handle fluctuating loads as and when needed.
Load Balancing
With horizontal scalability, EVA then distributes incoming network traffic across multiple servers (pods) to ensure that no single pod bears too much load. This is done with help of load balancers that route requests based on various algorithms.
Key takeaways
Here are the main points regarding EVA's strategy for database concurrency and load balancing:
Expand to See
Consistent Performance
- Efficient Load Balancing: The EVA platform uses advanced load balancing strategies to ensure that no single pod is overwhelmed, leading to consistent and responsive performance.
- Auto-Scaling: Automated scaling mechanisms allow the EVA platform to dynamically adjust resources based on demand, preventing bottlenecks during peak loads.
Data Consistency and Integrity
- ACID Compliance: All transactions adhere to ACID properties (Atomicity, Consistency, Isolation, Durability), guaranteeing data integrity.
- Isolation Levels: Configurable isolation levels (example, Read Committed) to manage transaction concurrency and avoid issues like dirty reads, non-repeatable reads, and phantom reads.
Concurrency Control Mechanisms
- Locking Mechanisms: Effective use of row-level and table-level object locking where relevant to prevent race conditions and ensure that concurrent transactions do not interfere with each other.
- Pessimistic Locking: For many critical objects that are updated concurrently, locking is in place at the application level. Additionally, when necessary, further concurrency control is applied to specific database records, allowing two processes to mutate the same record.
Fault Tolerance and Reliability
- Replication and Failover: Database replication and failover mechanisms are implemented. This ensures high availability and reliability. If one database node fails, another can seamlessly take over without data loss.
- Backup and Disaster Recovery: Regular backups and well-defined disaster recovery plans are in place to ensure that data is safe and can be restored quickly in case of a failure.
Scalability and Elasticity
- Sharding: Sharding strategies are employed to distribute data across multiple databases for horizontal scaling, reducing the load on any single database instance.
Improved Maintenance
- Easier Updates: Maintenance tasks like updates, backups, and security patches can be performed on individual instances without taking the entire platform offline, ensuring continuous availability.
- Reduced Downtime: For maintenance, individual nodes are isolated for maintenance, the overall platform remains operational, leading to minimal disruption for end users.
Enhanced Performance
- Efficient Resource Utilization: Load distribution helps in better resource utilization, ensuring that requests are handled swiftly and efficiently.
Observability and Monitoring
- Real-time Monitoring: Continuous monitoring of database performance and health, including metrics like query performance, lock wait times, and transaction rates is in place.
- Alerting and Logging: A proactive alerting mechanism and comprehensive logging for quickly identifying and resolving concurrency-related issues is in place.
Security
- Access Controls: Fine-grained access controls and permissions are implemented to ensure that only authorized transactions are performed by respective users, reducing the risk of data corruption from unauthorized concurrent access.
Release Cycle
Over time, EVA has grown into an extensive set of applications and modules. Although not all facets adhere to the same release schedule, they are consistently released and in a timely manner.
Releases are published centrally for all customers, allowing them to review the release notes for the latest versions, updates, and deprecations. The following four frontend functionalities are released uniformly:
More on release cycles can be found in the Introduction to releases page.
Customers will have a full release (four weeks) to update their versions, adopt the applicable changes introduced, and are allowed to be one release behind on our 'lastest-and-greatest'.